
Animaciones sintetizadas en Open 3D Engine. La Open 3D Foundation ha publicado la versión 22.05 de O3DE, la segunda versión estable del nuevo motor de juegos de código abierto AAA basado en el motor Lumberyard de Amazon Web Services.
Los cambios incluyen propiedades definidas por el usuario y materiales que se pueden mezclar varias veces para que los activos del juego se puedan actualizar fácilmente. Un nuevo sistema de coincidencia de movimiento para la síntesis de animación y actualizaciones del renderizador Atom de O3DE.
Además, el motor ahora tiene complementos de terceros para la solución de efectos de partículas en tiempo real PopcornFX. Y para transmitir datos geoespaciales en tiempo real desde plataformas como Cesium.
Un motor de juego de código abierto con capacidad AAA basado en Lumberyard de AWS. Anunciado por primera vez el año pasado, O3DE es un motor de juego de código abierto y multiplataforma publicado como sucesor de Lumberyard, el anterior motor gratuito de AWS.
Propiedades definidas por el usuario de O3DE
Cuenta con un diseño modular similar a un SDK, un sistema de construcción de código abierto y una nueva pila de redes. Incluye Atom, el renderizador RayTrace acelerado por hardware de la empresa. También disponible en código abierto. Ya habíamos publicado una vista previa sobre este motor de render en el Avance Atom render para Lumberyard; el motor de render que tiene en cuenta las reglas de la física real.
El renderizador, está destinado a ser más perfeccionista en una amplia variedad de escenarios, incluyendo los juegos. Un motor que trabaja de forma modular configurable mediante la escritura de archivos JSON. Está basado en una arquitectura subyacente, haciendo de Atom un renderizador de alto rendimiento con un diseño modular.
También está totalmente basado en datos, curiosamente, los usuarios pueden definir casi todas las características y configuraciones a través de archivos JSON. En lugar de codificación convencional, reduciendo el tiempo necesario para volver a compilar el motor.
Dispone de soporte para Vulkan y Metal, Shader basado en el propio AZSL. Atom de Amazon es compatible con las gráficas API DirectX, Vulkan y Metal. Será posible implementar en MacOS, así como plataformas compatibles existentes como Windows, Linux, Android e iOS.
Para trabajar el Shader, Atom utiliza AZSL (Amazon Shading Language), la propia extensión de HLSL de DirectX por parte de Amazon.
Soporte PBR y RayTrace en animaciones sintetizadas en Open 3D Engine
Soporta flujos de trabajo PBR y seguimiento de rayos, pero información limitada sobre las posibilidades gráficas. Las cosas se vuelven más vagas cuando se trata de las posibilidades gráficas del renderizador, no hay una lista detallada de características.
Tampoco hay material de archivo de Atom en acción, sólo imágenes fijas de simples escenas de prueba. Sin embargo, la entrada de blog dice que Atom admite sombreados basados físicamente a través de un flujo de trabajo metálico de rugosidad. Incluida la compatibilidad con materiales PBR multicapa.
Al igual que con otras características de Atom, los usuarios pueden definir materiales a través de archivos JSON. Los desarrolladores de Amazon son difíciles de trabajar diseñando una herramienta gráfica basada en nodos.
La entrada del blog también menciona que Atom soporta el rastreo de GI y rayos, reemplazando el GI basado en Voxel heredado. Además de varios documentos técnicos SIGGRAPH de efectos postales. El renderizado Forward+ estará disponible con la infraestructura para añadir renderizado diferido.
Avance Atom render para VFX y visualización, así como juegos. Amazon ve Atom como una plataforma en la que los usuarios pueden crear sus propias características avanzadas; en lugar de una que proporcione características avanzadas de inmediato.
O3DE con el respaldo de la fundación Linux
El motor es el primer lanzamiento de la nueva Open 3D Foundation respaldada por Linux-Foundation. Una contraparte del organismo de tecnología VFX Academy Software Foundation para la industria del desarrollo de juegos.
El nuevo sistema de propiedades definidas por el usuario permite realizar ediciones en los materiales asignados a los activos del juego dentro de aplicaciones DCC. Como Blender (izquierda) en lugar de dentro del Editor O3DE.
Las propiedades definidas por el usuario y los materiales remezclables hacen que los activos sean más fácilmente actualizables.
Los cambios clave en O3DE 22.04 incluyen la introducción de propiedades definidas por el usuario (UDP). Una forma de leer metadatos de los activos de origen en el procesador de activos.
El sistema hace posible que los artistas realicen cambios en los activos del juego en el software DCC como Blender o Autodesk Maya. Por ejemplo, cambiando los materiales aplicados a un modelo 3D, en lugar de dentro del editor O3DE.
Además de las mallas, UDP se puede utilizar para almacenar propiedades personalizadas para luces o nodos de animación. Los metadatos se pueden leer desde activos exportados en formatos de archivo 3D estándar, incluidos FBX y glTF.
Los archivos JSON de material ahora pueden hacer referencia a otro archivo desde el que cargar las propiedades base; luego anular cualquier valor que deba personalizarse para los submateriales, lo que reduce el código duplicado.
Coincidencia de movimientos personalizables
El nuevo sistema de coincidencia de movimiento genera animaciones personalizadas en tiempo de ejecución. La actualización también presenta un nuevo sistema experimental de coincidencia de movimiento, disponible como Gem: uno de los componentes modulares de O3DE.
Una técnica basada en datos, la coincidencia de movimiento sintetiza nuevas animaciones para un personaje. Lo hace extrayendo propiedades de un conjunto de datos de origen para que coincida con las entradas del jugador y el entorno del personaje.
Se puede utilizar para generar nuevas animaciones para un personaje a partir de datos de captura de movimiento no estructurados. Evitando la necesidad de organizar clips de movimiento en gráficos de animación o para crear transiciones explícitas entre ellos. El ejemplo Gem incluye un personaje prefabricado, controlable mediante un gamepad.
Este sistema se utiliza actualmente en Terrain de O3DE, TressFX hair physics y LyShine user interface Gems. Con desarrolladores capaces de agregar soporte para pases personalizados a otras Gem a través de un nuevo conjunto de API.
Niveles de presentación depurados
La actualización también agrega un componente de nivel de representación de depuración para depurar la iluminación de escena. Puede anular propiedades específicas para todos los materiales de una escena, mostrar normales o mostrar solo iluminación difusa o especular. Un nuevo componente CubeMapCapture captura un cubemap de entorno en cualquier ubicación del nivel.
Atom es ahora el renderizador predeterminado en la ventana gráfica del Editor de animación de O3DE; lo que hace que el rendimiento de renderizado sea comparable al del juego. El renderizador OpenGL heredado ha quedado obsoleto.
La actualización incluye actualizaciones del sistema de secuencias de comandos visuales Script Canvas de O3DE, prefabricados, controles de audio y Multiplayer Gem. Vemos nuevos plugins de Cesium y PopcornFX Desde la versión anterior, O3DE. El plugin PopcornFX implementa la solución de efectos de partículas en tiempo real dentro de O3DE, con código fuente disponible bajo la Licencia de la Comunidad PopcornFX.
Cesium for O3DE permite transmitir datos geoespaciales al motor en tiempo real, con el código fuente disponible bajo una licencia Apache 2.0.
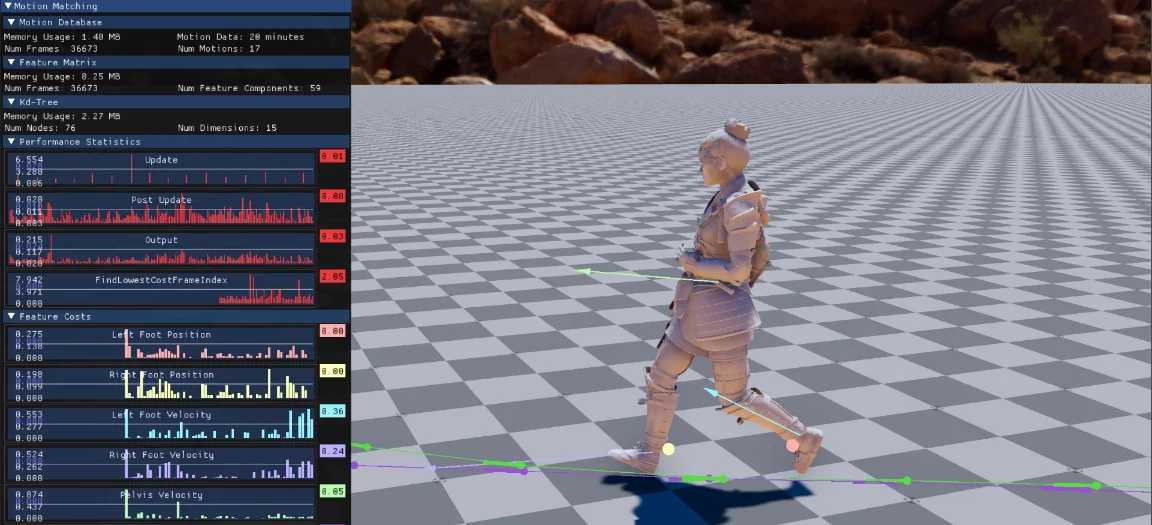
Coincidencia de movimiento en las animaciones
La coincidencia de movimiento es una técnica de animación basada en datos que sintetiza movimientos basados en datos de animación existentes y en los contextos actuales de carácter y entrada.
Cómo implementar esta herramienta
Agrega Gem al proyecto mediante el Administrador de proyectos o la Interfaz de línea de comandos (CLI).
Compila tu proyecto y ejecútalo.
Funciones de las animaciones sintetizadas en Open 3D Engine
Una función que es una propiedad extraída de los datos de animación y es utilizada por el algoritmo de coincidencia de movimiento para encontrar el siguiente mejor fotograma coincidente.
Ejemplos de características son la posición de las articulaciones de los pies, la velocidad lineal o angular de las articulaciones de la rodilla. O la historia de la trayectoria y la trayectoria futura de la articulación raíz. También podemos codificar sensaciones ambientales como las posiciones de obstáculos y la altura; la ubicación de la espada de un personaje enemigo o la posición y velocidad de un balón de fútbol.
Su propósito es describir un fotograma de la animación por sus características clave y, a veces, mejorar los datos reales del fotograma clave; como posición y escala por articulación. Por ejemplo, teniendo en cuenta el dominio del tiempo y calculando la velocidad o la aceleración; o una trayectoria completa para describir de dónde vino la articulación dada para llegar al marco y el camino por el que se mueve en un futuro próximo.



Las características configuramos cada uno de los siguientes puntos
Extraer los valores de función para un fotograma determinado en la base de datos de movimiento y guárdalos en la matriz de características. Por ejemplo, calcula la velocidad lineal de la articulación del pie izquierdo; conviértela en relación con el espacio del modelo de articulación raíz para el fotograma 134 y coloca los componentes XYZ en la matriz de características a partir de la columna 9.
Extrae la función del contexto/pose de entrada actual y llena el vector de consulta con ella. Por ejemplo, calcula la velocidad lineal de la articulación del pie izquierdo de la pose de caracteres actual en relación con el espacio del modelo de articulación raíz y coloque los componentes XYZ en el vector de consulta de entidades a partir de la posición 9.
Calcula el coste de la función para que el algoritmo de coincidencia de movimiento pueda sopesarla para buscar el siguiente mejor marco coincidente. Un ejemplo sería calcular la distancia al cuadrado entre un fotograma en la base de datos de coincidencia de movimiento; y la pose de caracteres actual para la articulación del pie izquierdo.
Las características se extraen y almacenan en relación con una articulación dada; en la mayoría de los casos la extracción de movimiento o la articulación de la raíz; por lo tanto están en el espacio del modelo. Esto hace que el algoritmo de búsqueda sea invariante a la ubicación y orientación del carácter y las características extraídas. Como por ejemplo, una posición conjunta o velocidad, se traduzcan y giren junto con el carácter.
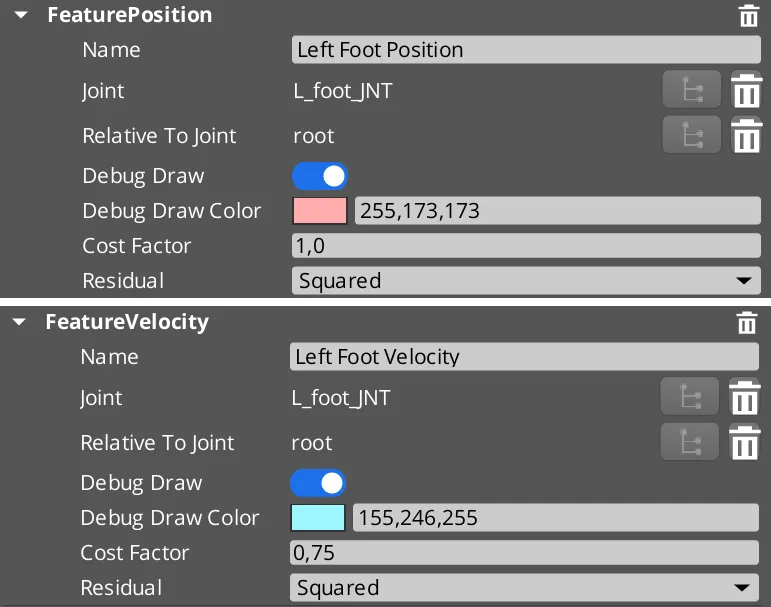
Descripción de propiedades en la interfaz de usuario
- Nombre: Nombre para mostrar utilizado para la identificación de características y las visualizaciones de depuración.
- Conjunto: Nombre conjunto para extraer los datos.
- Relativo a la articulación: Al extraer datos de entidades, conviértelos en espacio relativo a la articulación dada.
- Debug Draw: ¿Están habilitadas las visualizaciones de depuración para esta característica?
- Color de dibujo de depuración: color utilizado para las visualizaciones de depuración para identificar la función.
- Factor de coste: El factor de coste para la función se multiplica con el real; y se puede usar para cambiar la influencia de una función en la búsqueda de coincidencia de movimiento.
- Residual: Use Cuadrado en caso de que se deban ignorar las diferencias mínimas y las diferencias más grandes deben ponderar a otros. Usa Absoluto para diferencias lineales y no quiera el efecto mencionado.
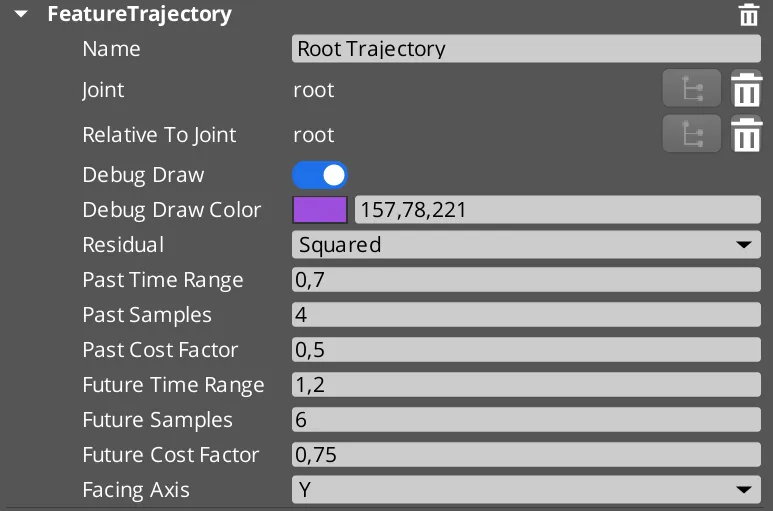
Características y configuración de la trayectoria en la animación
- Rango de tiempo pasado: La ventana de tiempo a lo largo de las muestras para el historial de trayectoria. Valor predeterminado = 0,7 segundos.
- Muestras pasadas: el número de muestras almacenadas por fotograma para la trayectoria pasada. Valor predeterminado = 4 muestras para representar el historial de trayectoria.
- Factor de coste pasado: El factor de coste se multiplica con el costo del historial de trayectoria; y se puede usar para cambiar la influencia de la coincidencia del historial de trayectoria en la búsqueda de coincidencia de movimiento.
- Rango de tiempo futuro: La ventana de tiempo a lo largo de la ventana de tiempo a lo largo de las muestras para la trayectoria futura. Valor predeterminado = 1,2 segundos.
- Muestras futuras: El número de muestras almacenadas por fotograma para la trayectoria futura. Valor predeterminado = 6 muestras para representar la trayectoria futura.
- Factor de costo futuro: El factor de coste se multiplica con el costo de la trayectoria futura; y se puede usar para cambiar la influencia de la coincidencia de trayectoria futura en la búsqueda de coincidencia de movimiento.
- Eje de orientación: La dirección de orientación del personaje. ¿Qué eje de la transformada articular está mirando hacia adelante? Predeterminado = Mirar en la dirección del eje Y.
Características para las animaciones sintetizadas en Open 3D Engine
El esquema de características es un conjunto de características que definen los criterios utilizados en el algoritmo de coincidencia de movimiento; e influyen en la velocidad de tiempo de ejecución. La memoria utilizada y los resultados del movimiento sintetizado. Es la entrada más influyente y definida por el usuario para el sistema.
El esquema define qué entidades se extraen de la base de datos de movimiento; mientras que los datos extraídos reales se almacenan en la matriz de características. Junto con el tipo de característica, se especifican configuraciones como la articulación de la que extraer los datos; un color de visualización de depuración, cómo se calcula el residuo o una función personalizada.
Cuantas más funciones selecciona el usuario, mayores serán las posibilidades de que la pose buscada y emparejada alcance el resultado esperado. Pero cuanto más lento será el algoritmo y más memoria se utilizará. La clave es utilizar elementos cruciales e independientes que definan una pose y su movimiento sin ser demasiado estrictos en el extremo equivocado. La trayectoria de la raíz junto con las posiciones y velocidades del pie izquierdo y derecho han demostrado ser un buen comienzo.
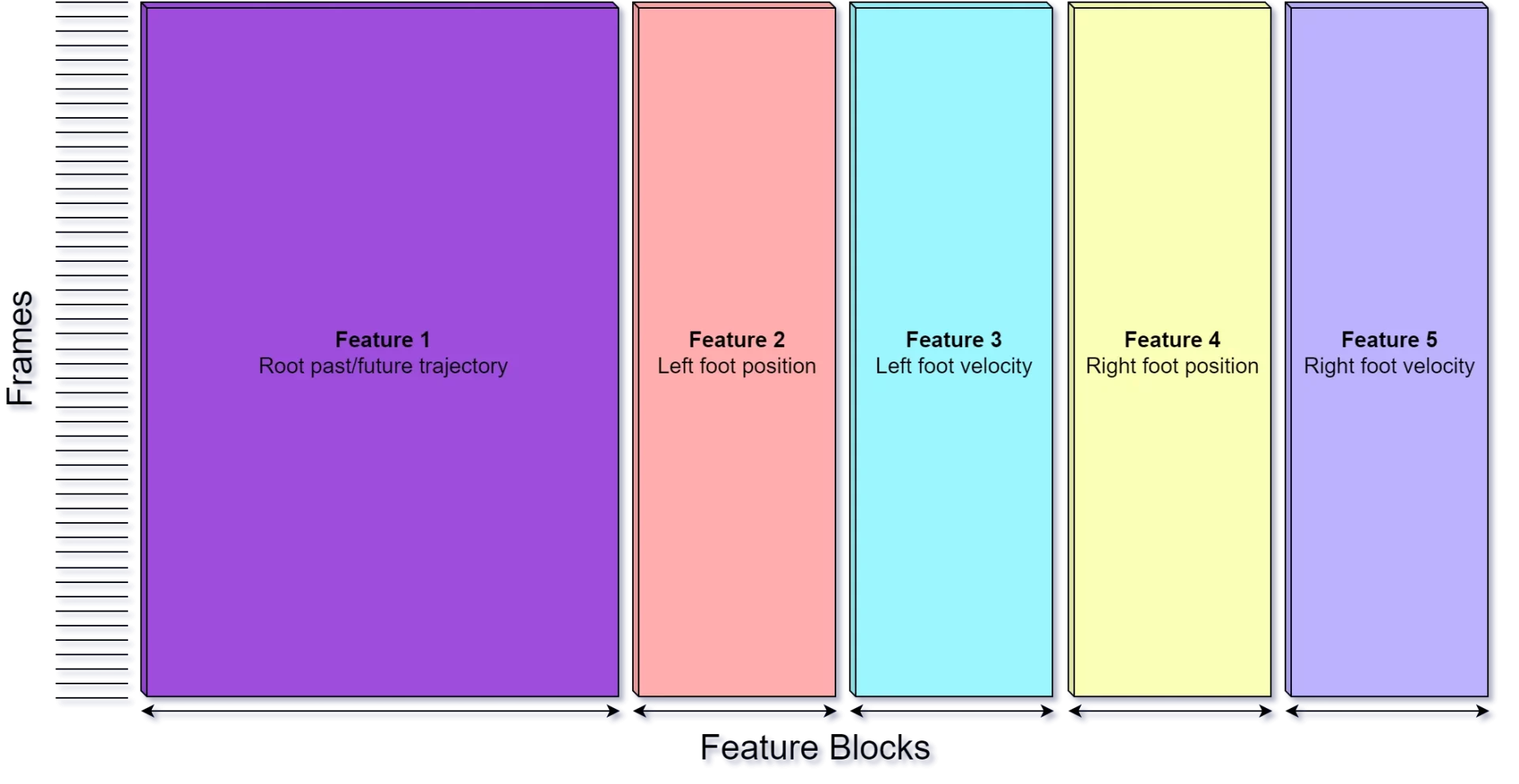
Matriz de características
La matriz de características es una matriz NxM que almacena los valores de característica extraídos para todos los fotogramas de nuestra base de datos de movimiento; en función de un esquema de entidad determinado. El esquema de entidades define el orden de las columnas y los valores; y se utiliza para identificar valores y encontrar su ubicación dentro de la matriz.
Una función de posición 3D que almacena valores XYZ, por ejemplo, utilizará tres columnas en la matriz de características. Cada componente de una función está vinculado a un índice de columna, por lo que; por ejemplo, el valor de la posición Y del pie izquierdo podría estar en el índice de columna 6.
El grupo de valores o columnas que pertenecen a una característica determinada es lo que llamamos un bloque de características. El número acumulado de cotas para todas las entidades del esquema; mientras que el número de cotas puede variar según la función, forma el número de columnas de la matriz de entidades.
Cada fila representa las características de un solo fotograma de la base de datos de movimiento. El número de filas de la matriz de entidades está definido por el número.
Uso de memoria en las bases de datos
Una base de datos de captura de movimiento que contiene 1 hora de datos de animación junto con una frecuencia de muestreo de 30 Hz para extraer características. Lo que resulta en 108.000 cuadros, utilizando el esquema de características predeterminado que tiene 59 características; dará como resultado una matriz de características que contiene 6.4 millones de valores y usa 24.3 MB de memoria.
Base de datos de frames en la animación
Un conjunto de fotogramas de las animaciones muestreadas a una frecuencia de muestreo determinada se almacena en la base de datos de fotogramas. Un objeto de fotograma conoce su índice en la base de datos de fotogramas; la animación a la que pertenece y el tiempo de ejemplo en segundos. No contiene la pose muestreada por razones de memoria, ya que ya almacena los fotogramas clave de transformación.
La frecuencia de muestreo de la animación puede diferir de la frecuencia de muestreo utilizada para la base de datos de fotogramas. Por ejemplo, sus animaciones pueden grabarse con 60 Hz mientras que solo queremos extraer las características con una frecuencia de muestreo de 30 Hz.
Como el algoritmo de coincidencia de movimiento se mezcla entre los fotogramas en la base de datos de movimiento mientras se reproduce la ventana de animación entre los saltos/mezclas. Puede tener sentido tener animaciones con una frecuencia de muestreo más alta que la que usamos para extraer las características.
Marcos de la base de datos
Se puede usar un marco de la base de datos de movimiento para muestrear una pose de la que podemos extraer las características. También proporciona funcionalidad para muestrear una pose con un desplazamiento de tiempo a ese marco. Esto puede ser útil para calcular las velocidades de las articulaciones o las muestras de trayectoria.
Al importar animaciones, los fotogramas que están dentro del rango de un evento de movimiento de fotograma de descarte se ignoran; y no se agregarán a la base de datos de movimiento. Los eventos de movimiento de descarte se pueden usar para recortar secciones de las animaciones importadas que no son deseadas. Como una parte de estiramiento entre dos cartas de baile.
El histórico de trayectorias
El histórico de trayectorias almacena la posición del espacio mundial; y los datos de dirección de la articulación raíz (articulación de extracción de movimiento) con cada tick del juego. El tiempo máximo de grabación es ajustable, pero debe ser al menos tan largo como la ventana de trayectoria pasada de la función de trayectoria como el historial de trayectoria se utiliza para crear la consulta para la función de trayectoria pasada.

Predicción de la trayectoria en la animación
El usuario controla al personaje por su trayectoria futura. La trayectoria futura contiene el camino por el que se espera que se mueva el personaje, si debe acelerar; moverse más rápido o detenerse, y si debe caminar hacia adelante haciendo un giro, o si debe caminar hacia los lados.
Basándonos en una posición de joystick, necesitamos predecir la trayectoria futura y construir el camino y los vectores de dirección de orientación a través de los puntos de control. La función de trayectoria define la ventana de tiempo de la predicción y el número de muestras que se generarán. Generamos una curva exponencial que comienza en la dirección del personaje y luego se dobla hacia el objetivo dado.
Datos de coincidencia de movimiento
Los datos basados en un esqueleto dado, pero independientes de la instancia, como la base de datos de captura de movimiento; el esquema de características o la matriz de características se almacenan aquí. Es solo un envoltorio para agrupar los datos compartibles.
Instancia de coincidencia de movimiento
La instancia es donde todo se une. Almacena el historial de trayectoria, la consulta de trayectoria junto con el vector de consulta; conoce el último índice de fotogramas de menor costo y almacena la hora de la animación que la instancia está reproduciendo actualmente.
Es responsable de la extracción de movimiento, mezclándose hacia un nuevo fotograma en la base de datos de captura de movimiento en caso de que el algoritmo encuentre un marco que coincida mejor y ejecute la búsqueda real.
En la imagen siguiente podemos ver la arquitectura
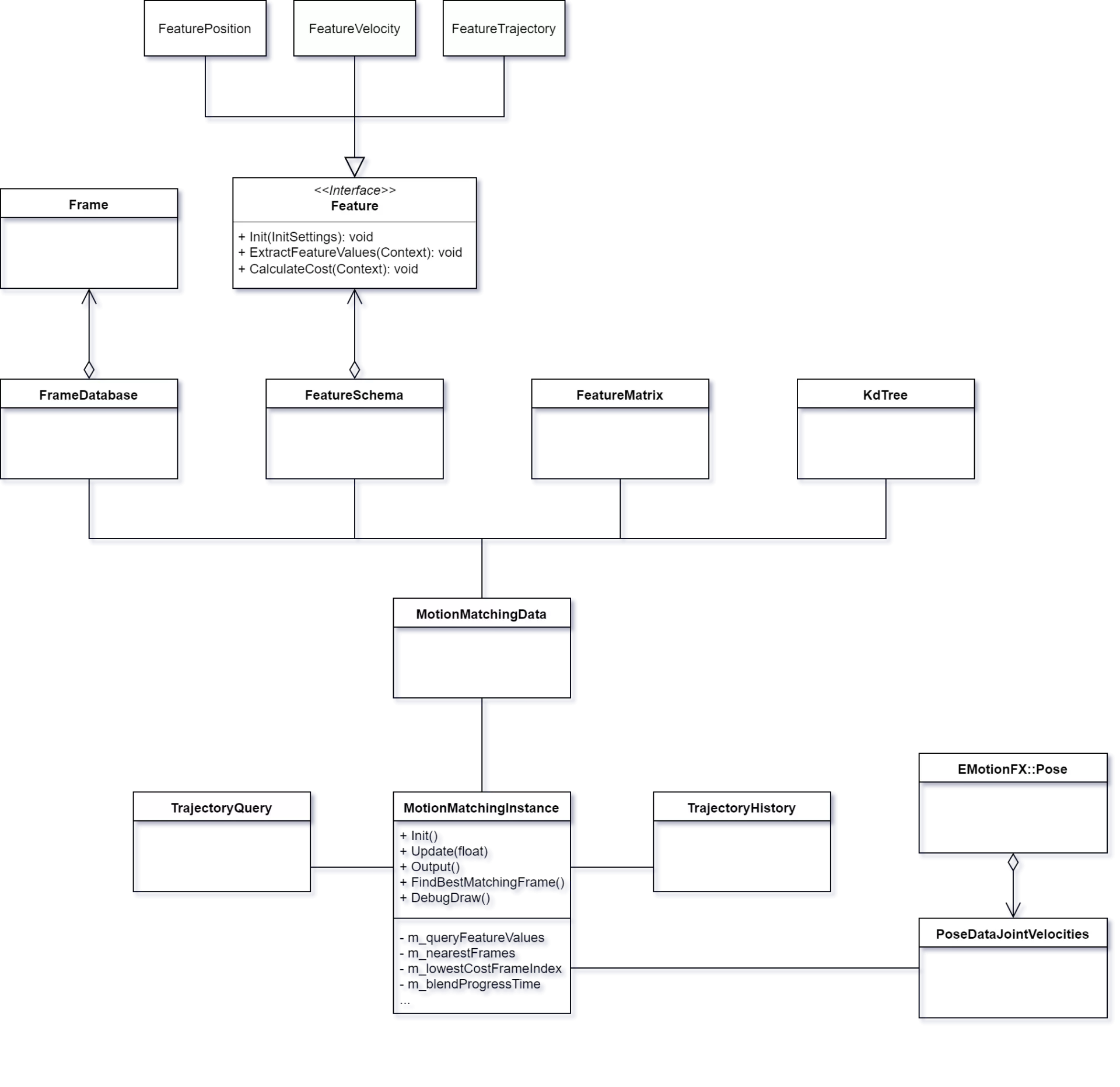
El algoritmo de coincidencia de movimiento
La coincidencia de movimiento reproduce pequeños clips de una base de datos de movimiento. Mientras salta y realiza una transición suave hacia adelante y hacia atrás, para sintetizar una nueva animación a partir de esos datos.
Bucle de actualización
En la mayoría de las marcas del juego, el movimiento actual avanza. Unas pocas veces por segundo, la búsqueda de coincidencia de movimiento real se activa para no alejarse demasiado de la entrada esperada del usuario. Ya que de lo contrario solo reproduciríamos la animación grabada.
Cuando se activa una búsqueda de un mejor fotograma de coincidencia siguiente, se evalúa la pose actual, incluidas sus velocidades conjuntas. Esta pose (que llamaremos pose de entrada o de consulta) se utiliza para rellenar el vector de consulta.
El vector de consulta contiene valores de entidad y se compara con otros fotogramas de la matriz de entidades. El vector de consulta tiene el mismo tamaño que hay columnas en la matriz de entidades y es similar a cualquier otra fila; pero representa la pose de consulta.
Usando el vector de consulta, podemos encontrar el siguiente mejor marco coincidente en la base de datos de movimiento y comenzar la transición hacia eso.
En caso de que el nuevo candidato a mejor fotograma coincidente esté cerca del momento en la animación que ya estamos reproduciendo; no hacemos nada, ya que parece que ya estamos en el punto óptimo en la base de datos de movimiento.
Pseudocódigo:
// Keep playing the current animation.
currentMotion.Update(timeDelta);
if (Is it time to search for a new best matching frame?) // We might e.g. do this 5x a second
{
// Evaluate the current pose including joint velocities.
queryPose = SamplePose(newMotionTime);
// Update the input query vector (Calculate features for the query pose)
queryValues = CalculateFeaturesFromPose(queryPose);
// Find the frame with the lowest cost based on the query vector.
bestMatchingFrame = FindBestMatchingFrame(queryValues);
// Start transitioning towards the new best matching frame in case it is not
// really close to the frame we are already playing.
if (IsClose(bestMatchingFrame, currentMotion.GetFrame()) == false)
{
StartTransition(bestMatchingFrame);
}
}Función de coste de recursos
La pregunta central en el algoritmo es: ¿A dónde saltamos y hacemos la transición? El algoritmo intenta encontrar el mejor momento en la base de datos de movimiento que coincida con la pose actual del personaje. Incluidos sus movimientos y la entrada del usuario. Para comparar los candidatos de marco entre sí, utilizamos una función de costo.
El esquema de características define la función de costo. Cada característica agregada al esquema de características se suma al costo. Cuanto mayor sea la discrepancia entre, por ejemplo, la velocidad actual y la del candidato del marco; mayor será la penalización al costo y menos probable es que el candidato sea bueno para tomar.
Esto hace que la coincidencia de movimiento sea un problema de optimización en el que el fotograma con el coste mínimo es el candidato preferido para la transición.
Búsqueda del siguiente mejor marco coincidente
La búsqueda real ocurre en dos fases; una fase amplia para eliminar a la mayoría de los candidatos seguida de una fase estrecha para encontrar al mejor candidato real.
Fase ancha (árbol KD)
Un árbol KD se utiliza para encontrar los vecinos más cercanos (fotogramas en la base de datos de movimiento) al vector de consulta (entrada dada). El resultado es un conjunto de fotogramas preseleccionados para el siguiente fotograma mejor coincidente que se pasa a la fase estrecha.
Al ajustar la profundidad máxima del árbol o el número mínimo de tramas para los nodos de hoja; se puede ajustar el número resultante de tramas. Cuanto mayor sea el conjunto de fotogramas que devuelva la fase amplia, cuantos más candidatos pueda elegir la fase estrecha; mejor será la calidad visual de la animación, pero más lento será el algoritmo.
Fase estrecha
Dentro de la fase estrecha, iteramos a través del conjunto devuelto de marcos del árbol KD, y evaluamos y comparamos su costo entre sí. El marco con el costo mínimo es la mejor combinación a la que hacemos la transición.
Pseudocódigo:
minCost = MAX;
for_all (nearest frames found in the broad-phase)
{
frameCost = 0.0
for_all (features)
{
frameCost += CalculateCost(feature);
}
if (frameCost < minCost)
{
// We found a better next matching frame
minCost = frameCost;
newBestMatchingFrame = currentFrame;
}
}
StartTransition(newBestMatchingFrame);Niveles de demostración y prefabricados
Hay dos niveles de demostración disponibles en el archivo. Copia y pega el contenido de la carpeta en la carpeta de niveles de proyecto para ejecutarlos de prueba. Gems/MotionMatching/Assets/Levels//Levels/
También hay dos prefabricados disponibles que puedes crear instancias en cualquiera de tus niveles existentes o en uno nuevo vacío para una prueba rápida:
- /Assets/AutomaticDemo/MotionMatching_AutoDemoCharacter.prefab: Demostración de coincidencia de movimiento donde el personaje se moverá y seguirá un camino en el nivel automáticamente.
- /Assets/AutomaticDemo/MotionMatching_ControllableCharacter.prefab: Demostración de coincidencia de movimiento donde puedes usar un gamepad para mover al personaje.

Histogramas de características
En la siguiente imagen puede ver histogramas por componente de entidad que muestran sus distribuciones de valores en toda la base de datos de movimiento. Pueden proporcionar información interesante; como por ejemplo, si la base de datos de movimiento contiene más animaciones de avance que animaciones de ametrallamiento; o movimiento hacia atrás, o cuántas animaciones de giro rápido vs lento hay en la base de datos.
Esta información se puede utilizar para ver si todavía hay una necesidad de grabar algunas animaciones o si algún tipo de animación está sobrerrepresentada; y conducirá a la ambigüedad y disminuirá la calidad de la animación sintetizada resultante.

Diagrama de dispersión con PCA
La siguiente imagen muestra nuestros datos de matriz de características de alta dimensión proyectados a dos dimensiones utilizando el análisis de componentes principales. La densidad de los clústeres y la distribución de las muestras en general indican lo difícil que es para el algoritmo de búsqueda encontrar un buen candidato a marco coincidente.
Los grupos en la imagen después de múltiples proyecciones aún pueden ser separables sobre una de las dimensiones disminuidas.
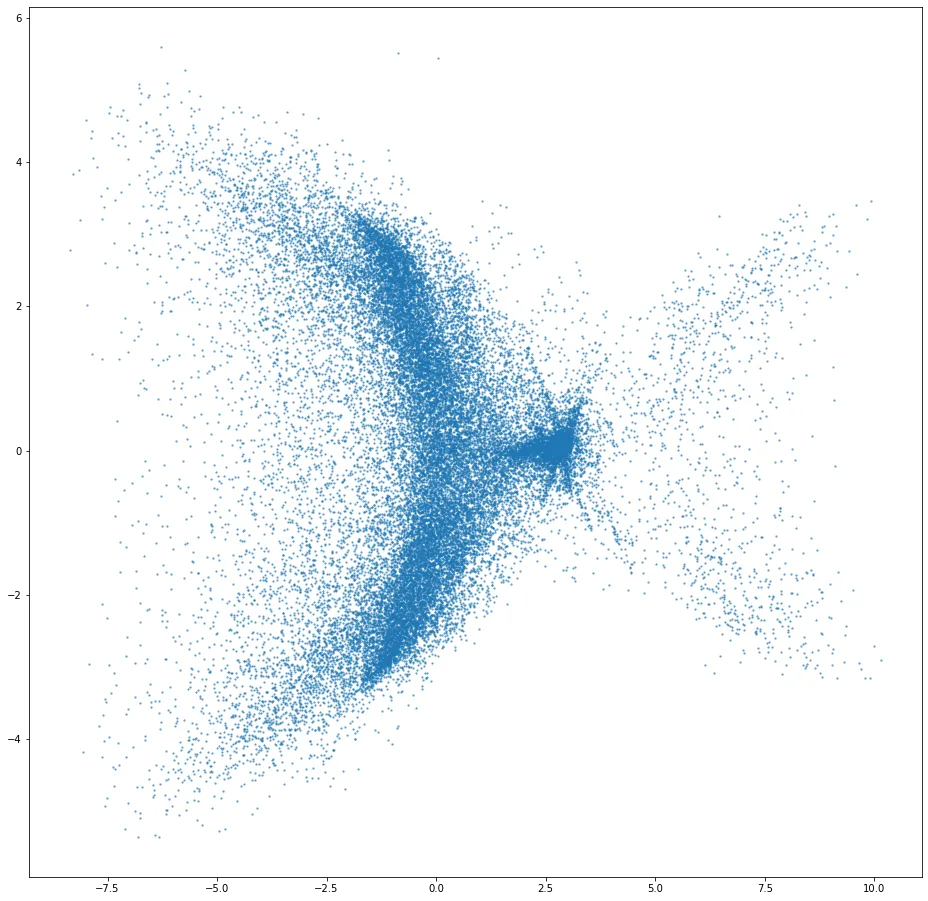
Las animaciones sintetizadas en Open 3D Engine sería la Motion Matching del O3DE
Motion Matching es una forma simple pero poderosa de animar personajes en los juegos. En comparación con otros métodos, no requiere mucho trabajo manual una vez que tiene una configuración básica. No hay necesidad de estructurar clips en gráficos, cortarlos o sincronizarlos cuidadosamente, o crear explícitamente nuevas transiciones entre estados.
Sin embargo, Motion Matching funciona mejor cuando se combina con muchos datos de captura de movimiento, y todos esos datos tienen un costo: un gran uso de memoria. Que solo empeora cuanto más crece el sistema y más situaciones en las que se aplica.
Aquí presentamos una solución a este problema llamada Learned Motion Matching que aprovecha el aprendizaje automático para reducir drásticamente el uso de memoria de los sistemas de animación basados en Motion Matching.
Coincidencia de movimiento
Primero, tratemos de entender cómo funciona Motion Matching en sí mismo. Un buen lugar para comenzar es examinando los datos con los que vamos a trabajar; animaciones largas y no estructuradas, generalmente de un conjunto de datos de captura de movimiento. Aquí hay una animación típica de dicho conjunto de datos:
Considera este problema: usando estos datos de origen, ¿Cómo podríamos animar un personaje para que siga este nuevo camino?
Con un buen conjunto de datos de animación, Motion Matching puede resolver este problema. Funciona buscando repetidamente en el conjunto de datos un clip que; si se reproduce desde la ubicación actual, haría un mejor trabajo al mantener el carácter en el trazado que el clip actual. El resultado en bruto es un mosaico de clips de animación, muy parecido a este.
Reproducción de las animaciones
Decidir cuándo comenzar a reproducir una nueva animación en lugar de continuar la animación que ya está reproduciendo es clave. Y elegir otro clip, es decir, dar un salto a un fotograma diferente de animación en nuestro conjunto de datos; requiere que seamos capaces de medir cuánto mejor o peor sería este cambio para nuestra tarea. Decidir exactamente cómo hacer esto es difícil, porque un solo fotograma de animación contiene mucha información. Parte de la información podría no ser útil para esta decisión.
Una buena solución es elegir a mano parte de esta información, que llamaremos características; y usarlas para decidir qué tan bien un cuadro de animación en particular coincide con la tarea. En este caso necesitamos características que expresen dos cosas el camino que va a seguir el personaje para que podamos ver qué tan similar es a nuestro camino deseado y la pose actual del personaje. Para que si empezamos a reproducir el nuevo clip no haya un gran cambio en la postura del personaje.
La experiencia ganada con cada paso
Con un poco de experimentación, podemos encontrar que las posiciones de los pies; sus velocidades, la velocidad de la cadera del personaje y un par de instantáneas de la posición y dirección de la trayectoria futura son las únicas características que necesitamos para lograr este camino siguiendo la tarea. Así es como se ven:
Esta información es mucho más compacta y manejable, no solo para nuestros ojos; sino también para el algoritmo que debe buscar una buena coincidencia en tiempo de ejecución. Si reúne todos los valores de característica de cada fotograma de animación en una matriz, obtiene un vector que llamamos vector de entidad.
Esta es una representación numérica compacta de la capacidad de este marco para realizar la tarea. Extraemos estas características para todos los fotogramas del conjunto de datos y apilamos los vectores resultantes en una matriz grande. A esto, lo llamamos la base de datos de características coincidentes.
Cuando llega el momento de decidir si debemos cambiar a un nuevo clip, formamos un vector de entidad de consulta a partir de la pose actual y la parte siguiente de la ruta deseada. Buscamos en la base de datos de características coincidentes la entrada que mejor coincida con la consulta.
Buscando la pose perfecta
Una vez encontrado, buscamos la pose completa correspondiente en el conjunto de datos de animación e iniciamos la reproducción desde allí. Aquí hay una visualización de la búsqueda y la mejor coincidencia que encuentra:
¿Qué pasa con ese molesto pop cuando inmediatamente cambiamos al siguiente clip? Pues aunque tenemos algunas características que capturan la postura actual del personaje también tenemos algunas que expresan la trayectoria futura. Incluir esas características de trayectoria es como aceptar intercambiar cierta discontinuidad de movimiento a cambio de la adherencia al camino.
Si el cambio en la postura no es demasiado grande, esta discontinuidad se puede eliminar fácilmente utilizando técnicas comunes. Como una mezcla corta de desvanecimiento cruzado o descomponiendo la diferencia entre los marcos de origen y destino de la transición, también conocida como inercia. Aquí está nuestro resultado con esta mezcla de inercia aplicada.
Finalmente, podemos aplicar un poco de bloqueo del pie y cinemática inversa para producir un resultado agradable y pulido.
Eso es todo
Al elegir diferentes tipos de características para que coincidan, podemos construir sistemas de animación que logren diferentes tipos de tareas. Como la interacción con accesorios, la navegación sobre terrenos accidentados o incluso las reacciones a otros personajes. Esta es la salsa secreta detrás de muchos de los mejores sistemas de animación en los juegos de hoy.
El problema de la escalabilidad
Ahora que sabe cómo funciona Motion Matching, piense en la cantidad de datos que se pueden requerir para una producción AAA. Bueno, depende del diseño. Hay muchos factores a considerar, como qué tipos de locomoción deseas soportar. Como: inactivo, caminar, trotar, correr, sprint, strafe lento, strafe rápido, saltar, saltar, agacharse.
Las acciones disponibles y sus parámetros; como: abrir una puerta, ir a sentarse en una silla, recoger un objeto, montar un caballo. Combinaciones como caminar, caminar mientras sostiene un arma ligera, mientras sostenía un arma pesada a dos manos.
Todo lo anterior está agravado por estilos de arquetipo (como sabores de civiles y soldados) y estados de juego (heridos, borrachos, etc.). Antes de que te des cuenta, tendrás muchos cientos de megabytes, tal vez gigabytes, de datos entrando en el sistema. Y, permíteme enfatizar un punto particularmente importante sobre Motion Matching: no combina datos.
Distintas animaciones para la ocasión
Si tienes una animación de caminar y otra para beber; Motion Matching no podrá producir una escena en la que el personaje esté caminando mientras bebe. Motion Matching solo reproducirá los datos que le proporciones.
Y, no solo tenemos que mantener todos estos datos de animación en la memoria, sino que también existe la base de datos de características coincidentes; que crece proporcionalmente al número de características y la cantidad de datos de animación utilizados. Naturalmente, buscar en una base de datos más grande también significa un rendimiento de tiempo de ejecución más pobre. Esta es la razón por la que decimos que Motion Matching escala mal en términos de datos.
Nuestro objetivo en esta investigación es simple: reemplazar la maquinaria Motion Matching con algo que produzca exactamente el mismo resultado. Pero que no requiera mantener tantos datos en la memoria. El flujo de trabajo para los animadores debe seguir siendo exactamente el mismo.
Permite crear el sistema que deseen utilizando Motion Matching y tantos datos como deseen. Luego, una vez que estén terminados, conecte un sistema alternativo que produzca el mismo resultado pero que tenga un menor uso de memoria y un costo constante de CPU. Aquí es donde entra en juego Learned Motion Matching.
Coincidencia de movimiento por aprendizaje
Para empezar, necesitamos pensar un poco más abstractamente sobre nuestro sistema de animación; y considerarlo más como un sistema lógico que toma como entrada alguna consulta de control (ya sea una ruta deseada a seguir. Posiciones de palanca del controlador y pulsaciones de botones, etc.) y produce como salida una animación continua y fluida.
Un sistema de animación basado en Motion Matching, como vimos; hace esto utilizando los datos de animación que se le suministran más la base de datos de características que busca periódicamente.
Para ser más específicos, podemos decir que una animación se describe mediante una secuencia de poses completas, cada una referenciada por un índice de fotogramas. Que es algo que apunta a dónde se almacena la pose en el conjunto de datos de animación. Reproducir un clip significa aumentar el índice actual en cada fotograma y buscar la pose completa correspondiente desde el conjunto de datos de animación.
La búsqueda de coincidencia de movimiento se realiza cada pocos fotogramas y funciona comparando las características de consulta con cada entrada en la base de datos de entidades coincidentes. Devolviendo el índice de fotogramas de la mejor coincidencia. A continuación, el mejor índice de fotogramas reemplaza al índice actual y la reproducción se reanuda desde allí. El siguiente diagrama resume esta lógica:
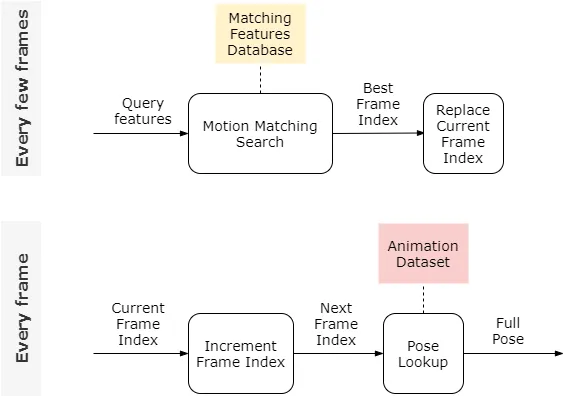
Trabajando sobre los conjuntos de datos
Primero pensemos en cómo podríamos eliminar el conjunto de datos de animación en este diagrama. Una idea es intentar reutilizar la base de datos de características coincidentes calculada para su uso en la búsqueda. Después de todo, las características almacenadas en esta base de datos capturan muchos aspectos importantes de la animación.
Entrenemos una red neuronal, llamada Descompresor; para que tome como entrada un vector de características de la base de datos de características coincidentes y produzca como salida la pose completa correspondiente. Con esta red, la lógica por fotograma ahora se ve así:
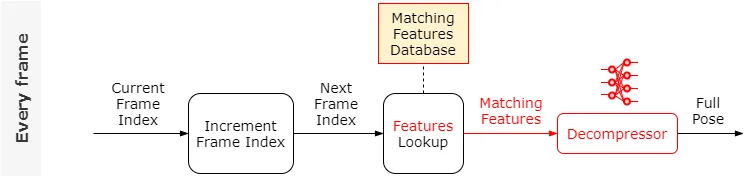
Cómo funciona Motion Matching con poses estándar
Veamos qué tan bien funciona esto en comparación con la búsqueda de pose estándar. A continuación puede ver una comparación entre el uso de la búsqueda de poses para generar la pose en gris y el uso del descompresor para generar la pose en rojo.
Podemos ver que aunque las animaciones son similares; ocasionalmente hay algunos errores visibles (mira las posiciones de las manos en el esqueleto del alambre a la izquierda). Esto se debe a que las características coincidentes no contienen suficiente información para permitirnos reconstruir la pose en todos los casos.
Sin embargo, la calidad de la animación reconstruida es sorprendentemente buena. En lugar de confiar solo en la base de datos de características coincidentes. ¿Qué pasa si le damos al Descompresor un poco de información adicional, como algunas características adicionales más?
De hecho, en lugar de elegir estas características adicionales a mano; podemos usar una red de codificador automático para extraerlas automáticamente (consulta el documento para obtener más información). El entrenamiento de este codificador automático nos da un vector de características adicionales por fotograma, seleccionado automáticamente para mejorar la precisión del descompresor.
Debemos almacenar estas características adicionales para todos los marcos en su propia base de datos de características adicionales junto con la base de datos de características coincidentes. Veamos qué significa eso para nuestra lógica.
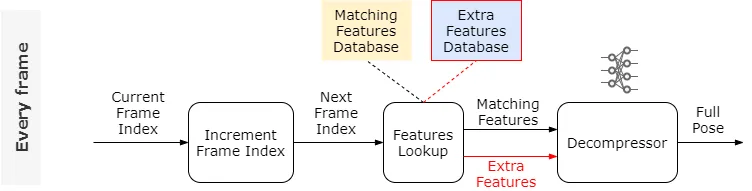
Las diferentes calidades utilizan características adicionales
Y aquí está la diferencia de calidad con estas características adicionales, donde Pose Lookup se muestra en gris; y el resultado utilizando el Descompresor y las características adicionales se muestra en verde:
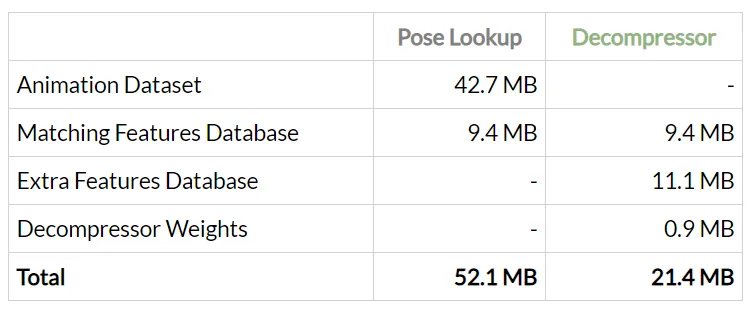
La salida es ahora casi completamente idéntica a las animaciones originales. ¿Cuánta memoria hemos ahorrado en el proceso?
Unir bases de datos de características coincidentes
Ahora que no tenemos que almacenar el conjunto de datos de animación en la memoria; hemos logrado disminuir significativamente el uso de memoria con cambios prácticamente imperceptibles en la salida. También hemos mantenido el comportamiento original de Motion Matching exactamente igual.
Desafortunadamente, el problema de escalabilidad no ha desaparecido por completo; las bases de datos de características adicionales y de coincidencia restantes aún crecen proporcionalmente al tamaño del conjunto de datos de animación original.
Primero, simplifiquemos nuestro diagrama uniendo la base de datos de características coincidentes y la base de datos de características adicionales en una base de datos de características combinadas. Por lo tanto, un vector de características combinadas para un fotograma dado es solo la concatenación de los vectores de características coincidentes y adicionales.
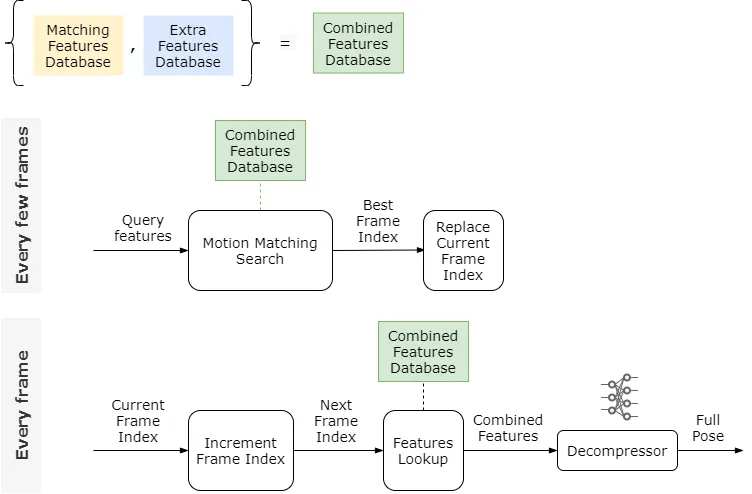
Dependencias de la base de datos
El siguiente paso es tratar de abordar la dependencia de la base de datos de características combinadas en cada fotograma. Aquí, en lugar de aumentar el marco actual y luego hacer la búsqueda de características, entrenaremos otra red neuronal, llamada Stepper; y la usaremos para predecir el vector de características combinadas del siguiente marco a partir del vector de características combinadas del marco actual.
Debido a que esperamos proporcionar transiciones con frecuencia (digamos 5 veces por segundo), el Stepper solo tiene que aprender a predecir durante un corto período de tiempo. Lo que lo hace pequeño en tamaño sin dejar de ser bastante preciso. Usando el Stepper la nueva lógica se ve como indica la imagen.
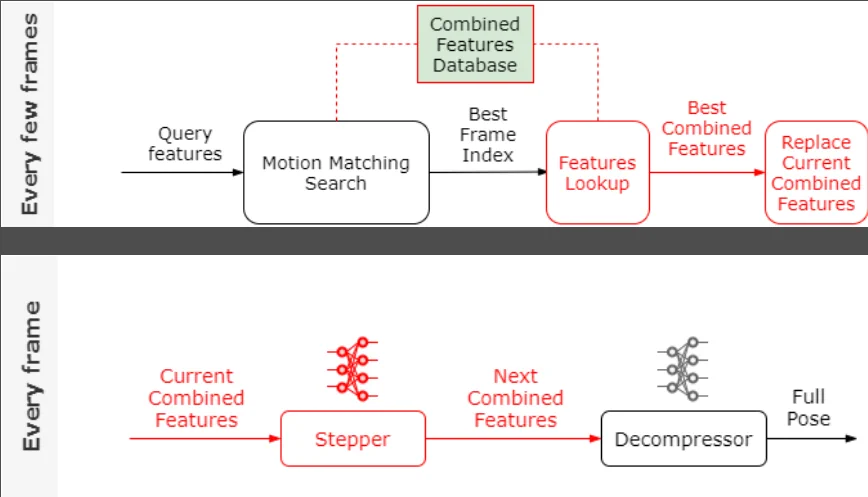
Desvincular la base de datos cuando ya no la necesitamos
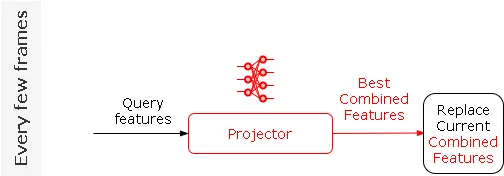
Ahora no necesitamos usar la base de datos de características combinadas en cada fotograma. Pero durante la etapa de transición todavía hay dos operaciones finales que dependen de tener la base de datos de características combinada en la memoria. La búsqueda de coincidencia de movimiento real y la búsqueda de características posterior.
Aquí, en lugar de buscar las mejores características coincidentes, buscar las características adicionales correspondientes y devolver el vector combinado. Vamos a entrenar una tercera red neuronal final, llamada Proyector, para predecir las características combinadas directamente desde el vector de consulta; esencialmente emulando la búsqueda y la búsqueda. Ahora podemos eliminar todas las bases de datos por completo.
Con todas esas redes entrenadas, la lógica completa de Learned Motion Matching se ve así:
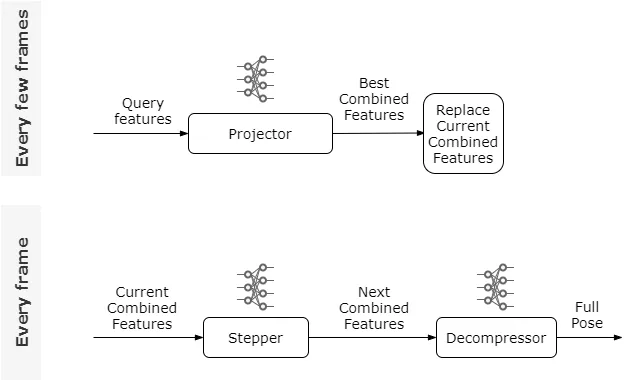
Esta lógica no solo es bastante simple, sino que al igual que encontramos con el Descompresor, si cada una de estas redes individuales se entrena con la suficiente precisión. La diferencia entre la coincidencia de movimiento aprendida y la coincidencia de movimiento básica es casi imperceptible. Aquí mostramos Learned Motion Matching aplicado a la misma ruta siguiendo el ejemplo que hemos estado usando:
Y aquí están los consumos de memoria involucrados:
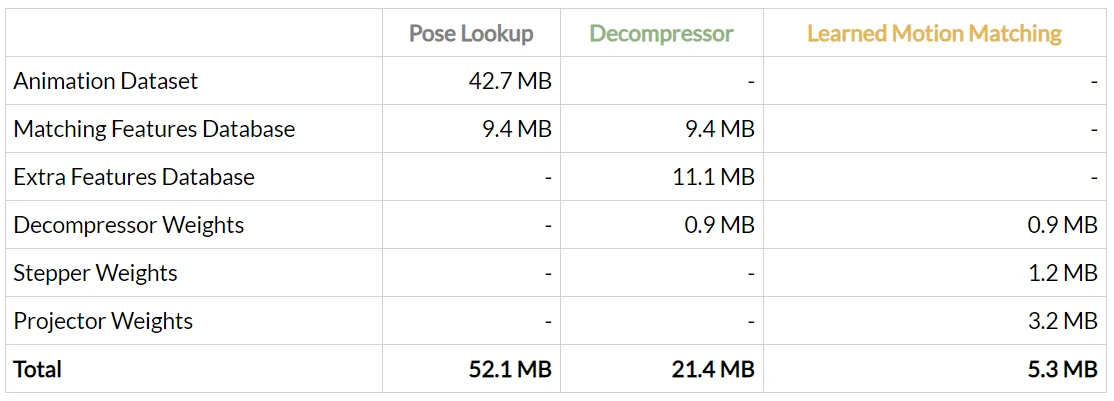
Entonces, para este ejemplo, Learned Motion Matching proporciona una mejora de diez veces en el uso de la memoria, ¡no está mal!
Sin embargo, si realmente queremos ver ganancias masivas, necesitamos aumentar sustancialmente el contenido de nuestro conjunto de datos de animación. En el experimento agregamos 47 nuevas articulaciones a nuestro personaje para incluir manos y dedos. Agregamos alrededor de 30 nuevos estilos de locomoción a nuestro conjunto de datos, todos ellos controlables a través de un interruptor.
Así es como se ve el controlador de locomoción interactivo Learned Motion Matching una vez que hemos agregado todos estos datos y entrenado a todas las redes involucradas:
Consumos de memoria involucrados de Learned Motion Matching
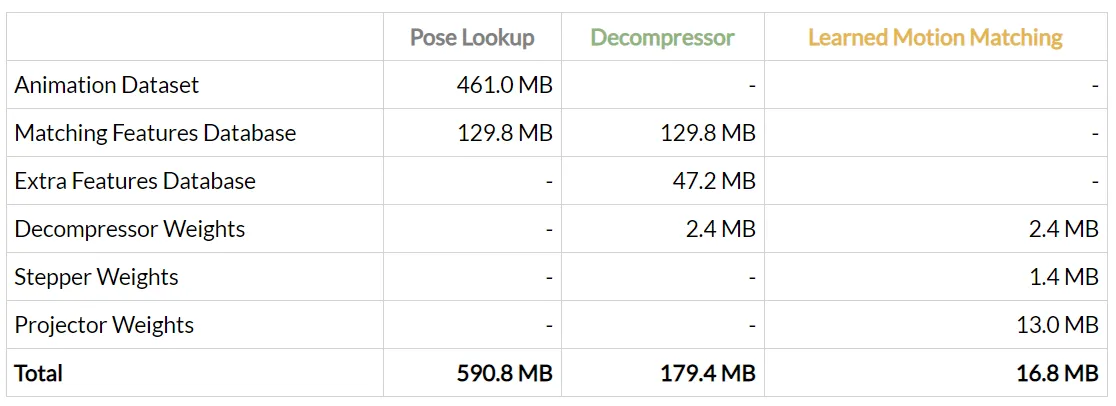
A pesar de que hemos agregado una gran cantidad de datos, incluidas muchas más articulaciones y características. Aumentando el uso de memoria de Motion Matching hasta más de medio gigabyte, el uso de memoria de Learned Motion Matching sigue siendo relativamente pequeño.
Al final, todo lo que necesitamos almacenar es alrededor de 17 MB de pesos de redes neuronales. Incluso encontramos que los pesos de red podrían comprimirse aún más por un factor de dos sin ningún impacto visual en el resultado al cuantificar a enteros de 16 bits. Si incluimos eso, podemos lograr una mejora de 70 veces en el uso de la memoria. Comprimiendo todo el controlador de 590 MB en 8.5 MB de memoria!
Por lo tanto, Learned Motion Matching es una forma potente; genérica y sistemática de comprimir sistemas de animación basados en Motion Matching que se escala a conjuntos de datos muy grandes. Al usarlo, se pueden lograr controladores de animación complejos y hambrientos de datos dentro de los presupuestos de producción; como en el siguiente video donde mostramos a los personajes caminando en un terreno irregular, interactuando sin problemas con otros personajes y accesorios. Cada personaje de esta escena está animado con Learned Motion Matching.
Esperamos que Learned Motion Matching pueda cambiar fundamentalmente lo que es posible con los sistemas de animación basados en Motion Matching. Y permitir a los artistas, diseñadores y programadores dar rienda suelta por completo a su creatividad, construyendo personajes que puedan reaccionar de manera realista y única a las miles de situaciones diferentes que se les presentan en el juego, sin tener que preocuparse por el impacto que podría tener en la memoria o el rendimiento.
Propiedades definidas por el usuario de O3DE
O3DE tiene la capacidad de que la canalización de activos de O3DE lea estos metadatos de propiedades definidas por el usuario (UDP). Para que la lógica de creación de escenas pueda personalizar la lógica de procesamiento de activos utilizando los metadatos de UDP.
Esto permite a los artistas seguir trabajando principalmente en las herramientas que han dominado como Autodesk Maya o Blender. Por ejemplo, un diseñador de contenido no necesitará abrir el Editor O3DE para asignar un material de ladrillo a un modelo de pared. Ya que el artista ha asignado el material de ladrillo al nodo de malla de pared en Blender.
Los artistas asignan metadatos en archivos de escena de origen (por ejemplo, extensiones de archivo blend, ma, 3ds). Para almacenar propiedades personalizadas sobre nodos de jerarquía como nodos de malla, luz y animación. Estos metadatos de propiedad definidos por el usuario se pueden exportar a archivos de activos de escena de origen (por ejemplo, FBX o glTF).
Los equipos de juego utilizan estos metadatos UDP para etiquetar los datos de malla con fines de motor, como dividir las mallas en nivel de detalles (LOD). Marcar una malla simplificada como una malla de colisión para usar como disparador o detección de golpes, y asignar características de escena como materiales de renderizado a los modelos de motor.
Iteración con otros programas DCC
La lógica de importación almacena claves de cadena asignadas a una variedad de tipos de valores. En la herramienta de creación de contenido digital (DCC), los artistas pueden almacenar tipos de valores de cadena, booleano; entero sin signo de 32 bits, entero con signo de 64 bits, flotante y doble para cada nodo. El artista deberá exportar explícitamente las propiedades de la escena al exportar el archivo de activos de origen de escena FBX (o glTF).
De forma predeterminada, los metadatos UDP no realizan acciones de creación de escenas; sino que los metadatos UDP se almacenan en el nodo del gráfico de escena cuando se importan a O3DE. En respuesta, la lógica de creación de escenas se puede actualizar para responder a los valores con clave para actualizar las reglas del manifiesto de escena.
Las reglas de manifiesto de escena se utilizan para crear modelos LOD, marcar mallas de colisión y asignar materiales. La lógica de creación de escenas se puede escribir en C++ o Python para actualizar el manifiesto de escena.
Asignación de materiales en la herramienta DCC
La propiedad scene se agregó a Gem prefabricada para asignar un recurso material mientras se ensamblaba una prefabricada de procedimiento predeterminada. La Gem prefabricada construye una prefabricada predeterminada para un gráfico de escena; busca el UDP en un nodo de datos de malla para definir un material de representación O3DE para ese grupo de malla dentro del prefabricado.
Esto permite a los artistas asignar materiales de renderizado O3DE en la herramienta DCC. Cada vez que se exporta el archivo de escena de origen, esta referencia se mantiene a través de la canalización de escenas.
Características que se implementarán próximamente
Hay muchas más características que se pueden desarrollar con la función de metadatos UDP. El motor puede eliminar la convención de nomenclatura de nodos blandos tanto para LODs (via ) como para la asignación de malla de colisión (via ); en su lugar podrían ser reemplazados por y , respectivamente.
Los equipos de juego pueden comenzar a agregar sus propias claves de metadatos de propiedad definidas por el usuario del proyecto único. Para asignar estadísticas de juego a mallas, mallas de oclusión y puntos de conexión. El equipo del juego actualizaría la lógica de un constructor de escenas para acceder y procesar con esas nuevas claves y valores de metadatos.
Uno de los objetivos de esta función es desbloquear la capacidad de ampliar la canalización de escenas para que los creadores de contenido tengan que ajustar menos los activos en el Editor O3DE. Y pasar más tiempo iterando para pulir un proyecto.

Disponibilidad y requisitos del sistema
Los binarios compilados de Open 3D Engine 22.05 están disponibles como descargas gratuitas para Windows 10 y Ubuntu 20.04+. El código fuente está disponible bajo una licencia Apache 2.0. Tienes más información sobre esta nueva versión en su blog.
Puedes encontrar más artículos sobre Open 3D Engine aquí. En el foro puedes encontrar toda la información agrupada y los comentarios. Sigue leyendo…