
Audio2Face genera mezclas faciales. Nvidia ha publicado Omniverse Audio2Face 2021.3.2, la última versión de su software experimental gratuito basado en IA para generar animación facial a partir de fuentes de audio.
La versión agrega la opción de generar un conjunto de formas de mezcla facial; estas formas abarcan una amplia gama de expresiones para personalizar los modelos a tu gusto. Luego puedes exportar los modelos en formato USD para editarlos en software DCC como Autodesk Maya o Blender 3. Sin olvidar su paso adelante para ser compatible con MetaHuman Creator, el software que genera personajes 3D de Epic Games.
Genera sincronización de labios automática y animación facial para personajes de Character Creator a partir de archivos de audio. Audio2Face es una herramienta entrenada por IA para generar animación facial sobre un personaje 3D a partir de fuentes de audio; grabaciones de voz o una transmisiones de audio en vivo.
Audio2Face 2021.3.2 incluye un reproductor de audio en streaming. Permite transmitir datos de audio al software desde fuentes externas como aplicaciones de texto a voz a través del protocolo gRPC.

Se puede utilizar conjuntamente con Omniverse Machinima
Junto con la aplicación hermana Omniverse Machinima; el software es una de un conjunto de nuevas herramientas de juegos que Nvidia está desarrollando en torno a Omniverse. Su nueva plataforma de colaboración en tiempo real basada en USD.
Esta versión de Audio2Face ofrece más opciones para controlar las animaciones faciales a través de su sistema de trabajo basado en la forma de mezcla facial. En la versión inicial, la única forma de modificar la animación que genera Audio2Face era a través de parámetros modificable solo mediante postproceso. Pero Nvidia ha empezado a implementar un flujo de trabajo alternativo basado en formas de mezcla facial.
Audio2Face genera mezclas faciales y además tiene ya lista para usar
El video que publicamos muestra el software que se utiliza para transferir un conjunto de 46 formas de mezcla listas para usar. Estas cubren una gama estándar de expresiones faciales desde el activo A2F a una cabeza totalmente personalizada.
El proceso de transferencia se puede controlar ajustando los puntos de correspondencia que identifican características equivalentes. Como las ubicaciones de los mismos rasgos faciales en los dos modelos de cabeza. El proceso conserva los UV, lo que permite reutilizar las texturas faciales originales.
Forma parte del paquete Omniverse
Audio2Face es una de las aplicaciones construidas como parte de Omniverse; una herramienta que simplifica el complejo proceso de animar una cara a una entrada de audio. Audio2Face fue desarrollado como una aplicación Omniverse; que se encuentra en la plataforma y lleva sus capacidades a otras aplicaciones integradas en el flujo de trabajo. La entrada es cualquier archivo de audio popular, como .wav o .mp3. y la salida es una animación facial realista, ya sea como una caché de geometría o como una transmisión en vivo.
Audio2Face es una tecnología basada en IA que genera movimiento facial y sincronización de labios completamente a partir de una fuente de audio. Audio2Face ofrece varias formas de explotar la tecnología. Se puede usar en tiempo de ejecución o para generar animación facial para canalizaciones de creación de contenido más tradicionales. Audio2Face también proporciona una canalización completa de transferencia de caracteres que proporciona al usuario un flujo de trabajo simplificado. Este permite conducir sus propios personajes con las tecnologías Audio2Face.
Audio2Face simplifica la animación de un personaje 3D para que coincida con cualquier pista de voz/audio. No está dirigido a la animación de gama alta de largometrajes. Sin embargo, proporciona excelentes personajes de animación de sincronización de labios en juegos, personajes de fondo NPC o para asistentes digitales en tiempo real.
Los usuarios pueden usar la aplicación para crear aplicaciones interactivas en tiempo real o trabajar sin conexión y exportar cachés para su uso en una canalización de animación facial tradicional. Audio2Face se puede ejecutar en vivo o bakear y exportar, depende del usuario.
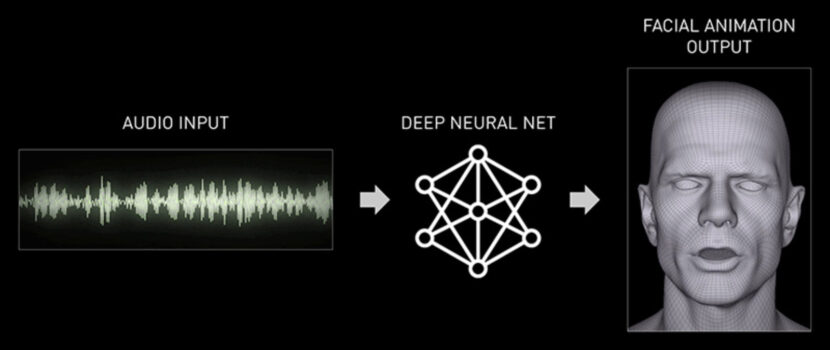
Aprendizaje profundo e inteligencia artificial de Audio2Face
Audio2Face surgió de una serie de reuniones alrededor de 2018 cuando varios desarrolladores de juegos llegaron a Nvidia y dijeron: «Oye, ya sabes, la escala de nuestros juegos ahora es tan grande. ¿Qué puede hacer NVIDIA, tal vez con la ayuda del aprendizaje profundo u otra tecnología, para ayudar a acelerar y satisfacer estas demandas de producción?», explicó Simon Yuen, Director de Gráficos e IA de NVIDIA. En ese momento, no era raro que un equipo de desarrollo de juegos estuviera en captura de movimiento durante dos años y medio seguidos, solo para un juego.
Estos problemas de producción realistas más la dificultad general (proceso lento y laborioso) de crear animación facial 3D de alta calidad «nos llevaron a comenzar a pensar en cómo resolver estos problemas. Queremos encontrar una solución que pueda acelerar y simplificar las animaciones faciales basadas en el habla», añade.
La aplicación utiliza el motor de render RTX ya que Audio2Face es parte del marco Omniverse. No pretende ser una aplicación de demostración, es una herramienta para permitir a los desarrolladores crear aplicaciones serias. Por ejemplo, es de esperar que esto se integre con MetaHuman de Epic, lo que permite que Audio2face conduzca personajes UE4 en tiempo real. Omniverse ofrece la ida y vuelta de activos dentro y fuera de programas como Unreal Engine 4 y Autodesk Maya.
Hay muchas características aún por venir o a punto de ser lanzadas
Por ejemplo, Audio2Face tiene un conjunto de controles de inferencia de publicación que le permiten ajustar las poses resultantes de la animación de salida en función de los datos entrenados. Esto le permite ajustar la amplitud de su rendimiento, entre otras cosas. También habrá formas de permitir al usuario cambiar o combinar diferentes emociones para afinar las expresiones y respuestas del personaje. Todos estos podrán ser animados en una línea de tiempo que permita a los usuarios desvanecerse de emociones como el asombro; la ira, el disgusto, la alegría, el dolor, etc. en un lanzamiento futuro.
Las versiones posteriores incluirán características más detalladas basadas en audio, que incluyen:
- Ojos y mirada.
- Dientes y lengua.
- Movimiento de la cabeza (asentimientos, etc.), utilizando una estructura conjunta, todo impulsado por audio.
- Además, controles de alto nivel para que puedas dirigir rápidamente el estado de ánimo y la emoción del personaje.
Todo impulsado por audio con controles de usuario adicionales. El objetivo es utilizar una interfaz muy simple para obtener un rendimiento completo de alta calidad; sin mucho del trabajo que tiene que hacer tradicionalmente en CG.
Algunos de los saltos de comportamiento plausible son nada menos que notables. Solo para subrayar este punto.
Nvidia Research está utilizando el aprendizaje automático para producir una animación plausible de lo que los ojos de un personaje. Lo están haciendo basándose solo en formas de onda de audio!
Hemos entrenado los ojos para que hagan un movimiento sádico natural, y luego puedes controlarlo o amplificarlo si lo necesitas. Puedes tener compensaciones si quieres encima de eso para controlar dónde se ve el personaje.
Mezclando emociones en próximas actualizaciones
En una versión futura, las emociones de los personajes también se pueden mezclar. Piense en una combinación de posturas FACS integradas en una red neuronal; para que no tengas que conducir cada forma FACS individualmente para el flujo de trabajo común laborioso y experto requerido. Estamos buscando cómo podemos mezclar y combinar emociones para obtener el rendimiento que necesitamos. El sistema anima no solo la piel de la cara de un personaje; sino también la cara completa, los globos oculares, los párpados, el movimiento de la cabeza, los dientes, la lengua y el cuello. Todos estos aspectos están controlados por la animación impulsada por audio y moderados por los vectores emocionales.

Yeongho Seol, Ingeniero Senior de Tecnología para Desarrolladores, demostró el control de emociones en GTC 2021. La recopilación de datos para los datos de entrenamiento de ML se basó en la captura del rendimiento facial 4D con audio sincronizado.
Esto incluyó actuaciones de discursos con varios estados emocionales. Junto con imágenes de referencia y moldes de los dientes del actor; el equipo de NVIDIA construyó un complejo modelo 3D de línea de base 3D de alta gama para entrenar la red neuronal profunda.
Audio2Face forma parte de los SDK de IA de Nvidia
Audio2Face es una de las muchas aplicaciones de los SDK de IA de Nvidia. Otro equipo está trabajando en nuevas API avanzadas de texto a voz (TTS) y bloques de construcción que el CEO de Nvidia. Jensen Huang, señaló en su discurso de apertura en la conferencia GTC 2021, comentando sobre no más voces que suenen a computadora. Nvidia tiene un marco completo para la IA conversacional; desde el reconocimiento automático de voz y el procesamiento del lenguaje natural hasta el texto a voz (TTS). Con síntesis de voz mediante espectrogramas Mel.
Nvidia lanzó Jarvis 1.0 Beta, que incluye un flujo de trabajo de extremo a extremo para crear e implementar aplicaciones de IA conversacional en tiempo real. Como transcripción, asistentes virtuales y chatbots a fines de febrero de 2021.
Por supuesto que te suena el software, hemos publicado artículos anteriores a este sobre Audio2Face. También tienes más información y comentarios en el foro, sigue leyendo…
Puedes descargar Audio2Face aquí.